
The blog series ‘In Focus‘ is conceived as a way to show the scope and diversity of the RELICS research group. Each month one of us will reflect on a current or recently finished project, and how it connects to the aims and vision of RELICS. Through this, by drawing from our own personal experience, we want to show in which ways Latin cosmopolitanism came to the fore from antiquity until modern times.
by Jeroen De Gussem (Ghent University)
In the early 1960s, a duo of American statisticians named Mosteller and Wallace published a pioneering book that carried major implications for philology. Reading the first lines of the opening chapter, one may sense from the authors’ mixed tone of vulnerability and smugness an awareness of the dust about to be stirred up in the pages to follow: “When two statisticians, both flanks unguarded, blunder into an historical and literary controversy, merciless slaughter is imminent.” Nonetheless, Mosteller and Wallace were keen to cross swords, so they continued: “our persistence needs explanation.”
Mosteller and Wallace are the founding fathers of what is known today as computational stylistics (or stylometry) and non-traditional authorship attribution. Their “literary controversy” was titled Inference and Disputed Authorship: The Federalist (1964). In its exploration of the disputed, pseudonymous Federalist Papers, the book takes the reader through demonstrating that authors’ individual language use is composed of patterns and writing tics that can be statistically aggregated and analyzed, almost like a kind of DNA in our writing. Especially the frequencies of a set of small, insignificant yet commonly used markers in English such as ‘enough,’ ‘whilst,’ ‘upon’ and ‘the’, so-called function words, provide valuable lexical features to segregate authors’ writing styles. This, of course, was Mosteller and Wallace’s controversy: algorithms can learn recurring patterns in our individual linguistic expressions, model a linguistic profile, and consequently predict with an astonishing accuracy who wrote an unattributed text. It is remarkable how the book provided such a hard case for individual expression just mere years before Roland Barthes would proclaim the author dead.
In this blog post, I would like to confront Mosteller and Wallace’s most important discovery, namely the individuality of style and so-called stylistic ‘features,’ with cosmopolitanism and Latin’s literary history. This confrontation is one that has arisen time and again from my own research, which is situated at the intersection of computer science, cultural history and Latin literature. Although the precept of individuality of style may sound acceptable in the context of spoken, natural languages, one may readily question it in the context of quite unspoken and —arguably so— quite unnatural languages, such as Latin. For most of its history, it was an acquired tongue, taught and learned by means of a normative literary tradition and institutionalized in the Church, schools and courts, providing a common, authoritative written lingua franca throughout Europe. This says something about status. How does Latin’s ‘sharedness’ relate to individuality? Can an artificial language that has been on life support in the schools for most of its history really be anything else than an acquired language, instead of internalized, personalized or customized? Moreover, the bulk of Latinity has been achieved under a long stretch of time, in which the understanding of ‘individual creation’ and ‘individuality’ was under constant development. Current-day notions of authorship closely associate individuality of expression with text appropriation and text ownership, but during most of Latin’s literary history, i.e. before the arrival of mechanic printing, copyright protection or electronic publication, notions such as plagiarism or impersonation were often interpreted quite flexibly. Material context is key when explaining these developments. Premodern authors relied strongly on oral preparation, and sometimes cooperated with scribes or assistants. Writing activity was less isolated than today, and texts’ forms were arguably more subjected to alterations both before and after they started circulating. Does such a history not irrevocably make any quest for an ‘individuality’ in style an impossible matter?
First the good news. Despite these caveats, my own modest observations in applying computational stylistics to Latin (see Figure 1) alongside those of many others whom I take seriously (further reading below) have led me to a firm conviction that stylometry is efficient for performing authorship attribution for Latin. Aside from some exceptions to the rule, stylometric experimentation for Latin literature consistently indicates that Latin writers do testify of individual traits in their writing styles, traits that distinguish them on a statistical basis, and often —as Mosteller and Wallace had shown in their groundbreaking book— depend on a small number of syntactic and grammatical words in the language such as prepositions, conjunctions, adverbs, pronouns and particles. Figure 1 gives an intuition of how a routine analysis works with three medieval Latin authors (The French, twelfth-century abbot Suger of Saint-Denis and his two secretaries). An original document is divided into smaller segments, the most common (function) words in the text(s) are aggregated, and the counted patterns (word frequencies) can be analyzed or cast into a visualization. Same-authored text samples will almost without exception be found to cluster together. Despite common backgrounds, shared literary traditions and values, or similar historical contexts, Latin authors generally tend to be very much like themselves, and very much unlike other authors.
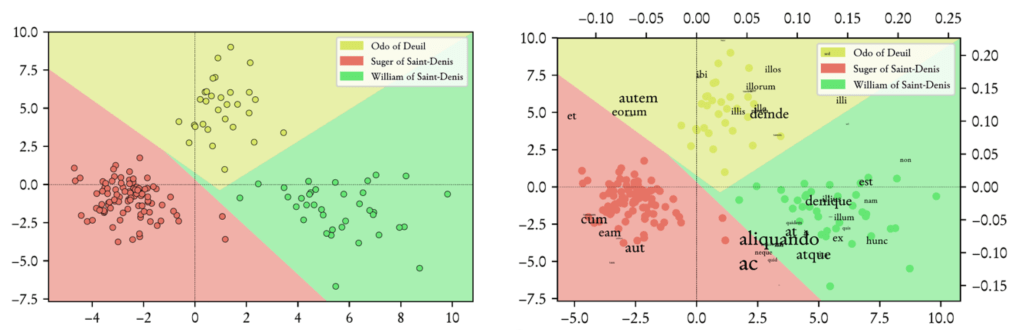
So far the sales pitch. Pragmatic and even inspiring as such examples may be, taking the leap from “telling apart authors” to “saying anything meaningful about the differences” when it comes to personality and literary contextualization is exceptionally difficult. Abstract, mathematical patterns constitute the true difference in style in these distant readings instead of semantic, isolated elements, which would perhaps have been easier to conceptualize and explain. One cannot possibly venture into retracing all the individual recurrences of these small words to re-interpret the computer’s output as a close reader: such a task is, on average, impossible in scope, and risky as there are no prospects of success in this department. These linguistic remnants of personal style, demonstrating the individual contributions of Latin authors to historical texts, may in the end simply be stating the obvious. Yes, a human being from the past wrote this text, and (s)he has certain writing tics: congratulations, you have now spotted them.
Latin is particularly frustrating when it comes to finding satisfactory, explanatory models for what is “under the hood,” arguably more so than spoken natural languages. Concerning the latter I could refer, for instance, to psycholinguist James Pennebaker, who argues in The Secret Life of Pronouns that there are psychological motives behind why some speakers of English prefer to use certain function words over others. The language of suicidal poets would contain more references to the first person singular (‘I,’ ‘me,’ ‘myself’), and women would be more prone to use personal pronouns and ‘certainty words.’ However, imagine scanning Ovid for his personal pronouns? Would you trust these patterns to say anything ‘personal’ about the poet? Most writers in Latin literary history did not exactly have their hearts on their sleeves.
For these and other related reasons, stylometrists still experience difficulties in formulating apt responses to the needs of Latinists. Even though the latter group could perhaps benefit more from the analysis of larger patterns in texts than they believe. Latinists have already developed an appetite for thinking about the larger connections between Latin and other literary traditions. Stylometrists could assist with upscaling and breaching traditional disciplinary, linguistic and generic demarcations, and with fulfilling those tasks which are too demanding and time-consuming to satisfactorily fulfill in a traditional close-reading framework. Stylometry can strike connections across time periods, genres and, as of late, even languages. Increasingly so, computational methods could be of help not only in questioning the relationship between sets of texts, but also the relationship between sets of literary cultures. Computers may help make processable what is Latin’s essence and its adaptability: which feature(s) make it similar or dissimilar.
Whenever you are having trouble ordering your thoughts: try statistics for a change. The concept of ‘feature’ struck me as a helpful way of thinking about stylometry’s potential contribution to Latin literary scholarship. ‘Features’ are those individual measurable properties or characteristics that define an observation. In theory, when one sums up a phenomenon’s features, one will arrive at an intimate and perfect knowledge of that phenomenon. A bird spotter would, for instance, be able to classify an unknown bird as a bald eagle (y) if features such as ‘rearrangeable feathers’ (x1), ‘lightweight’ (x2), ‘aerodynamic’ (x3) and ‘fast’ (x4) are applicable. Is it possible to transcend the level of individuality, and could there be an objective, verifiable ‘feature’ to why literary scholars attribute certain characteristics and theoretical concepts to literatures as a whole, such as —in the current context— ‘cosmopolitanism’? Computers alone will not be able to solve these discussions. But as machines become better learners, and arguably start understanding human beings’ language use better than themselves, they may have a role to play in future literary scholarship by facilitating a fresh take on ongoing discussions in Latin literary studies, and, who knows, come across some ‘features’ of Latin literary culture hitherto unnoticed by the scholarly community.
Further reading
- Craig, Hugh. “Authorial Attribution and Computational Stylistics: If You Can Tell Authors Apart, Have You Learned Anything About Them?” Literary and Linguistic Computing 14.1 (1999): 103–13.
- De Gussem, Jeroen. “Collaborative Authorship in Twelfth-Century Latin Literature. A Stylometric Approach to Gender, Synergy and Authority.” Ph.D. Dissertation, Ghent University and University of Antwerp, 2019.
- Eder, M. “A Bird’s Eye View of Early Modern Latin: Distant Reading, Network Analysis and Style Variation’. Early Modern Studies after the Digital Turn. Ed. Laura Estill, Diane K. Jakacki, and Michael Ullyot. Toronto: Iter Press, 2016. 61–88.
- Kestemont, Mike, Sara Moens and Jeroen Deploige. “Collaborative Authorship in the Twelfth Century: A Stylometric Study of Hildegard of Bingen and Guibert of Gembloux.” Digital Scholarship in the Humanities 30. 2 (2013): 199–224.
- Mosteller, Frederick and David L. Wallace. Applied Bayesian and Classical Inference: The Case of the Federalist Papers. 2nd ed. Springer Series in Statistics. New York: Springer Verlag, 1984 (1964).
- Pennebaker, James. The Secret Life of Pronouns. What Our Words Say About Us. New York: Bloomsbury Press, 2011.
- Stella, Francesco. “Generic Constants and Chronological Variations in Statistical Linguistics on Latin Epistolography.” Analysis of Ancient and Medieval Texts and Manuscripts: Digital Approaches. Ed. Tara Andrews and Caroline Macé. Turnhout: Brepols, 2014. 159–79.
